第 19 节 · 上下文管理策略:截断 / 摘要 / 分层 / GSSC
一句话回答
上下文管理不是越压越好,而是在"少带噪声"和"别丢关键事实"之间做取舍。 截断、摘要、分层、GSSC 复杂度逐步上升,控制力也逐步上升。
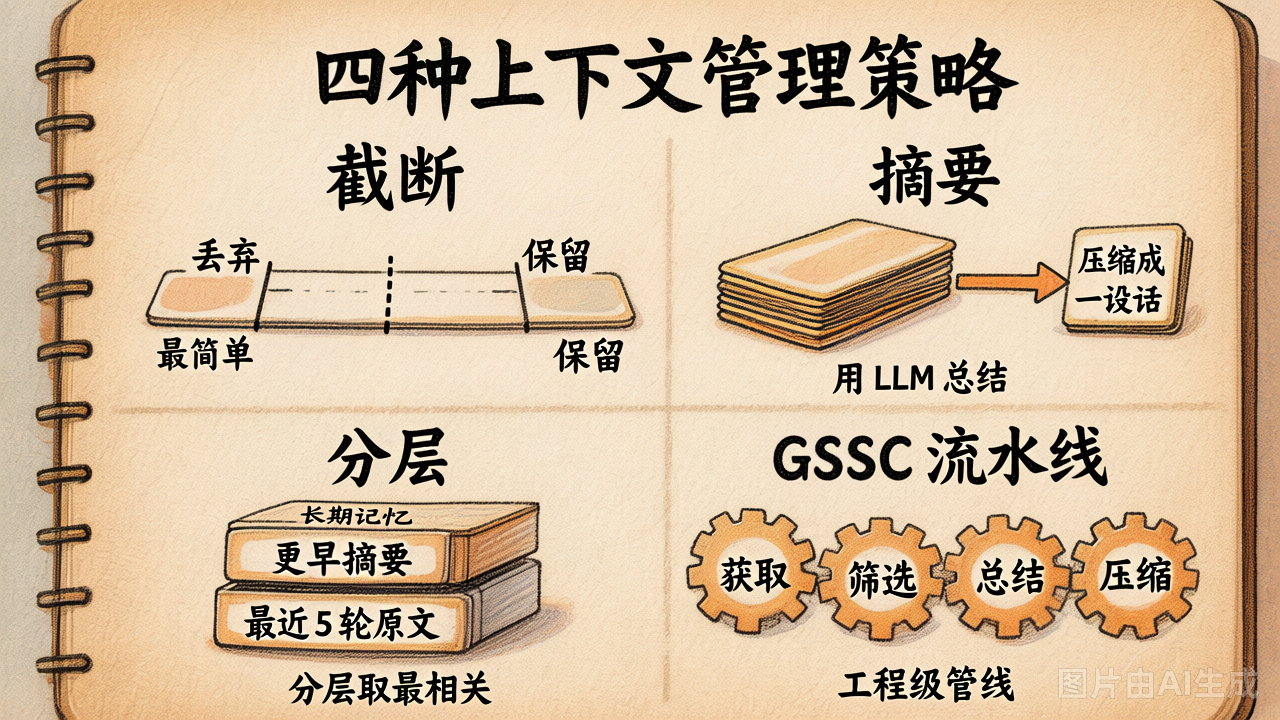
策略 ① 截断(Truncation)
做法
保留 system + 最近 N 条 messages,直接砍掉中间。工程上建议按完整 turn 裁切。
def truncate(messages, keep_last=6):
sys_msgs = [m for m in messages if m["role"] == "system"]
recent = messages[-keep_last:]
return sys_msgs + recent优缺点
✅ 极简,10 行内搞定 ✅ 没有任何 LLM 额外调用,零成本 ❌ 早期的"重要事实"(用户偏好 / 硬约束)一旦过了 N 轮就消失 ❌ 用户会感觉"AI 突然忘了我说过的话"
适合场景
- 客服类短对话(用户的硬约束都在最近几轮里)
- 演示场景(要简单跑通看效果)
⚠️ 一个常见的坑
很多人写截断时不保留 system,直接 messages[-keep_last:]。这样系统提示也被砍了,模型行为完全跑偏。system 必须永远保留。另外,最好按完整 turn 裁切,不要把一次 tool call 的请求和结果切散。
策略 ② 摘要(Summary)
做法
system + LLM 摘要的"早期对话" + 最近 N 条原文。
def summary(messages, keep_last=6):
sys = [m for m in messages if m["role"] == "system"]
middle = [m for m in messages if m["role"] != "system"][:-keep_last]
recent = messages[-keep_last:]
summary_text = llm.summarize(middle) # ← 多花一次 LLM 调用
return sys + [{"role": "system", "content": f"[早期摘要]\n{summary_text}"}] + recent优缺点
✅ 信息保留度比截断好得多 ✅ token 节省效果明显(中间一段几千 token → 一段 200 字摘要) ❌ 多一次 LLM 调用(成本 + 延迟) ❌ 摘要质量靠 LLM —— 关键事实可能被漏掉、改写或失去来源
让摘要更靠谱的两个 trick
trick 1:明确告诉 LLM 摘要要保留什么
SUMMARY_PROMPT = """请压缩成 100 字以内的中文摘要。
**特别保留:** 用户偏好、硬约束、关键事实、未完成的任务。
**可以丢弃:** 客套话、重复确认、模型的解释性回复。
"""trick 2:让 LLM 输出结构化摘要
- 用户偏好: 喜欢博物馆,不喜欢拥挤景点
- 已确认事实: 6月去北京 7 天
- 未决问题: 第 3 天行程未定结构化摘要比"一段话"对后续模型更友好。生产里还会保留来源、时间和置信度,方便之后发现摘要错了能回溯。
策略 ③ 分层(Hierarchical)
做法
每条信息按"距离当下任务的相关度"分三层:
[原始 system] ← 角色 / 工具 / 规则
[关键长期事实] ← 用户的硬约束(独立抽出来)
[早期对话摘要] ← LLM 压缩
[最近 N 条原文] ← 不动
+ user 当前问题关键事实怎么找?最朴素的做法是关键词匹配:
KEY_FACT_KEYWORDS = ["过敏", "预算", "重要", "对了", "一定要", "不要"]
def extract_key_facts(messages):
facts = []
for m in messages:
if m["role"] == "user" and any(kw in m["content"] for kw in KEY_FACT_KEYWORDS):
facts.append(m["content"])
return facts更进阶:用一个小模型做命名实体识别 / 关系抽取,或者直接让大模型做"事实抽取"。但抽取出来的事实也要允许更新和删除,否则长期事实会变成新的噪声源。
优缺点
✅ 关键事实跨越任意多轮也能保住 —— 这是分层最大的价值 ✅ 工程上很灵活:每一层独立可调 ❌ 实现复杂度比截断/摘要高一档 ❌ 关键事实抽取本身可能漏(关键词没覆盖的情况)
适合场景
- 多轮长对话 + 用户会不断补充硬约束(典型:旅行规划、工程咨询)
- Coding Agent(用户提需求时常说"对了,注意 X",这种约束必须跨越所有工具调用记得住)
策略 ④ GSSC 流水线
NOTE
GSSC 是本课为了教学起的缩写,不是行业标准名。2026 年很多文章会把类似思想概括成 write / select / compress / isolate:该外存的外存,该检索的检索,该压缩的压缩,该隔离的隔离。
做法
把上下文构造看成一个 4 阶段流水线:
| 阶段 | 做什么 |
|---|---|
| Gather(获取) | 从对话历史 / Memory / 工具 / 文件系统拉所有可能相关的信息 |
| Select(筛选) | 按当前任务相关度打分,扔掉不相关的 |
| Summarize(总结) | 长内容压缩 |
| Compose(组装) | 按特定结构(system / facts / examples / context)拼成最终 messages |
这类 pipeline 是生产 Agent 的常见思路:不要把所有东西一股脑塞进窗口,而是把"找什么、选什么、压什么、怎么摆"拆成可单独优化的模块。
跟 04-my-agent 对应
仓库里 examples/full-agent/context/context_builder.py 就是一个 GSSC 风格实现。今天不要求你写 GSSC,但要求你看懂它。
适合场景
- 真实生产系统
- 团队级 Agent(多个上下文源并存:会话 / 文档 / 代码 / Skills)
怎么选
| 任务特点 | 推荐策略 |
|---|---|
| 演示 / 短对话 | ① 截断 |
| 中等长度对话 / 单一任务 | ② 摘要 |
| 多轮 + 用户不断补约束 | ③ 分层(今天 lab 实现这个) |
| 真实工业级 Agent | ④ GSSC,并配合缓存、检索、权限和 eval |
实际工程里经常组合:
- 主链路用分层
- system / 关键事实 这两层不参与压缩
- 早期摘要这一层跑 GSSC 风格的 select + summarize 子流水线
- 多 agent / 多子任务之间做 context isolation,不共享一大坨历史
一个真实数据
我们 demo_19_context_strategies.py 里跑了一段 30 轮对话,第 2 轮埋了"过敏"事实,第 28 轮埋了"预算"事实。这个 demo 跑的是 RAW baseline + 前三种策略;GSSC 作为工程版思路放在讲义里理解:
| 策略 | messages 条数 | 字符数 | "过敏" 保住? | "预算" 保住? |
|---|---|---|---|---|
| RAW 不处理 | 57 条 | 897 字符 | ✅ | ✅ |
| ① 截断(最近 6 条) | 7 条 | 103 字符 | ❌ 被砍了 | ✅ |
| ② 摘要 | 8 条 | 取决于摘要长度 | ⚠️ 看 LLM 摘得好不好 | ✅ |
| ③ 分层 | 9 条 | 摘要 + 关键事实 | ✅ 关键事实抽出来了 | ✅ |
跑一遍你会发现,关键事实保留不能靠运气,要靠规则、抽取器和评测样例。
动手试试
cd labs/04-context-and-memory
python demo_19_context_strategies.py看 RAW baseline + 3 种入门策略的输出对比,特别注意"过敏"这个早期事实在每种策略下还在不在。
小结
| 策略 | 一句话理解 |
|---|---|
| ① 截断 | 砍掉中间,保留头尾 |
| ② 摘要 | 中间用 LLM 压缩成一段话 |
| ③ 分层 | 关键事实独立抽出来,跨越任意压缩 |
| ④ GSSC | 工程级 4 阶段流水线,把获取、筛选、压缩、组装拆开 |
下一节:上下文管理是"本次对话的事"。但用户的偏好、约束、习惯——这些应该跨会话存活。这就是 Memory 系统。