第 1 节 · LLM 为什么具备智能
一句话回答
LLM 运行时的基本动作很简单:给定前面一串 token,预测下一个 token 最可能是什么。
但它之所以表现出"智能",不只是因为会接龙,而是因为这个接龙器经过了:
- Transformer 架构:能在长文本里建立联系
- 海量预训练:从文本、代码、书籍中压缩语言和世界规律
- 后训练对齐:学会按人类期望回答问题
- 推理时计算:复杂问题上可以多花 token 进行思考
- 工具系统:在 Agent 场景中可以搜索、读文件、运行代码
纯模型本身不是数据库,不会真的"查找"答案;它是在做概率预测与采样。但现代 AI 产品常把模型接上搜索、文件、代码执行等工具,此时最终回答就是"模型推理 + 工具结果"的组合。
Next-Token Prediction
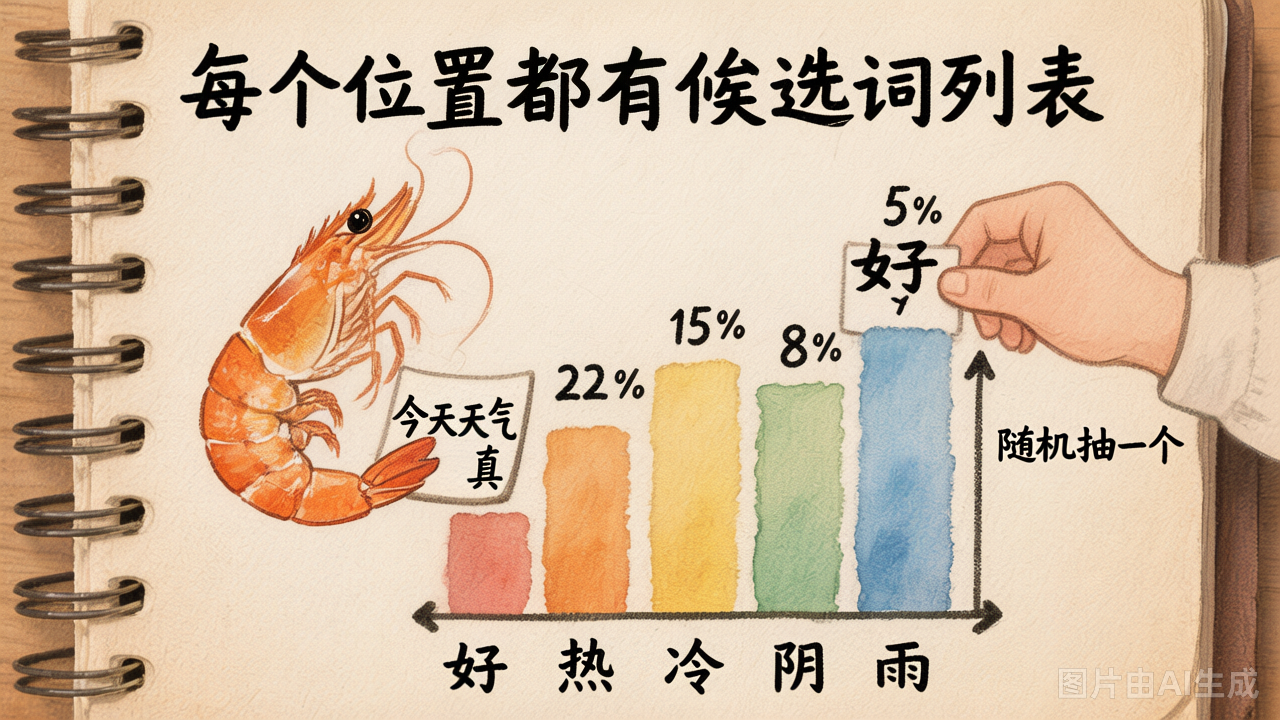
先看一个直觉例子。假如输入是 "今天天气真",模型内部会算出一张"下一个 token 的概率分布":
"好" → 35%
"热" → 22%
"冷" → 15%
"不错" → 8%
"糟糕" → 5%
......然后从这个分布里采样一个 token 输出(比如选了"好")。接着,把 "今天天气真好" 当成新的输入,再算下一个 token 的分布,再采样——如此循环,直到生成完毕。
Temperature:控制"随机程度"的旋钮
采样时有一个关键参数叫 temperature(温度)。它决定了模型从概率分布里"怎么选":
| temperature | 行为 | 适合场景 |
|---|---|---|
| 0 | 通常选概率最高的那个,输出最稳定 | 代码生成、事实问答 |
| 0.3 ~ 0.7 | 大概率选高分词,偶尔冒险 | 日常对话、写作 |
| 1.0+ | 更均匀地随机采样,输出更发散 | 头脑风暴、创意写作 |
NOTE
temperature 是 [0, 2] 范围内的连续浮点数,上表只是三个有代表性的档位。0.2、0.55、1.3 等任意值都合法——比如 0.2 行为接近 0、但允许极小扰动,常用于代码生成场景。
直觉理解:temperature 越高,概率分布越"平坦",低概率的词也有机会被选中;越低,分布越"尖锐",高概率的词几乎必选。
这就是为什么:
- 同一个问题,每次回答可能不同——因为
temperature > 0时它在随机采样 temperature = 0时通常更稳定——但真实 API 仍可能因为服务端实现、模型版本或并行计算出现细微差异
你可以用 demo_01_next_token.py 亲眼看到这个过程。
为什么"预测下一个 token"能学到知识
听起来只是接龙,为什么会变得像智能?
因为要把下一个 token 猜准,模型不能只背前一个词。它必须学会很多隐藏规律:
- 语言规律:什么词能接在什么词后面,句子怎样才通顺
- 事实关联:看到"地球围绕",高概率应该接"太阳"
- 代码模式:看到
def fibonacci(n):,后面可能是递归、循环或边界判断 - 任务意图:用户说"帮我总结",下一段应该是摘要,而不是继续提问
- 长程依赖:前文说"钥匙放在抽屉里",后文问"它在哪",要能指回"抽屉"
所以,next-token prediction 是训练目标;为了做好这个目标,模型内部会形成大量关于语言、知识、代码和推理模式的压缩表示。
模型怎么学会"预测得准"
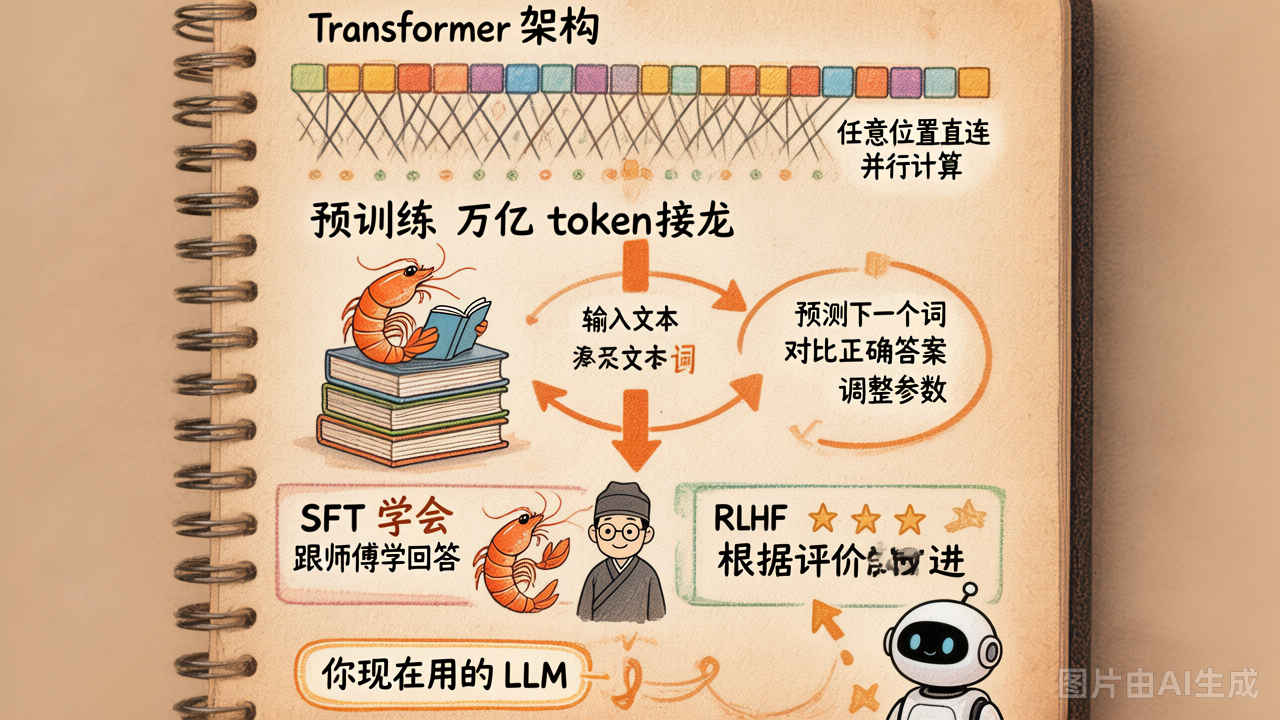
1. 架构:Transformer
LLM 的底层架构叫 Transformer。你不需要看懂数学,只需要知道它的核心能力:
Attention(注意力)机制——在预测下一个 token 时,模型能"回头看"前面所有 token,并决定重点关注哪些。
比如预测"他把钥匙放在了___"的下一个词时,模型会重点关注"钥匙"和"放",而不是句首的"他"。正是这个能力让 LLM 能处理几千甚至几十万 token 的长文本。
另一个关键优势:Transformer 在训练时能并行处理整段文本中所有位置的预测,而不需要从头到尾一个字一个字地算。这意味着可以用成千上万块 GPU 同时训练——这就是为什么模型能在合理时间内"读完"海量甚至万亿级 token 的数据。
2. 预训练(Pre-training)
第一步叫预训练,本质就是不断做"完形填空":
┌─────────────────────────────────────────────────────────┐
│ 训练语料: "今天天气真好,我去公园散步" │
│ ↓ 遮住一个位置 │
│ 问题: "今天天气真___" │
└───────────────────────────┬─────────────────────────────┘
↓
┌───────────────────────────┴─────────────────────────────┐
│ 模型回答: "不错" (12%) 正确答案: "好" │
│ │
│ ❌ 猜错了! │
└───────────────────────────┬─────────────────────────────┘
↓
┌───────────────────────────┴─────────────────────────────┐
│ 调整参数(拧旋钮): │
│ "好" 的概率: 12% ──→ 35% ⬆️ │
│ "不错" 的概率: 12% ──→ 6% ⬇️ │
└───────────────────────────┬─────────────────────────────┘
↓
下次答得更准!
↓
┌─────────────────────────┐
│ 重复海量次数 → 模型学成 │
└─────────────────────────┘一句话总结:出题 → 答题 → 对答案 → 调参数 → 下次答得更准。
把这个过程在海量 token 上重复(题目来自文本、代码、书籍、网页等数据),模型就"见多识广"了:
- 语法规律——知道中文句子该怎么接
- 世界知识——知道"地球围绕太阳转"
- 代码模式——看到
def fibonacci(n):知道后面该写递归
但此时模型只是个"文本接龙机"——你问它问题,它可能继续编问题,而不是回答你。
3. 后训练:让模型学会当助手
第二步叫后训练。它的目标不是继续扩大知识面,而是让模型更像一个可用的助手:
| 阶段 | 做什么 | 效果 |
|---|---|---|
| SFT(监督微调) | 用"人类提问 → 优质回答"的示范数据继续训练 | 模型学会以对话格式回答 |
| RLHF(基于人类反馈的强化学习) | 人类对多个回答排序打分,模型学习"人类更喜欢哪种回答" | 回答更有帮助、更安全、更符合人类偏好 |
| DPO(Direct Preference Optimization) | 直接用偏好数据优化模型,不单独训练 reward model | 流程更简单,常用于偏好对齐 |
简单类比:预训练 = 读遍所有书,SFT = 实习跟着师傅学怎么回答,RLHF / DPO = 根据用户偏好继续改进。
2025-2026 最新趋势
后训练已经不只是"让回答更礼貌"。它正在变成提升推理能力的关键环节:
- RLVR(Reinforcement Learning with Verifiable Rewards)——在数学、代码等有明确答案的任务上,用"答对/答错"作为奖励信号。
- GRPO(Group Relative Policy Optimization)——DeepSeek-R1 使用的重要强化学习方法之一,用一组回答的相对好坏来估计优势,减少训练成本。
- 推理模型(Reasoning Models)——OpenAI o 系列、DeepSeek-R1、Claude extended thinking 等模型,会在复杂任务上消耗更多 reasoning tokens 来计划、验证和修正。
一句话:前沿模型的进步,正在从"训练时更大"扩展到"后训练更强、推理时更会分配计算"。
小结
Transformer 架构(能处理长上下文)
↓
预训练(海量 token 上学"接龙")
↓
SFT / RLHF / DPO(学会当助手)
↓
RLVR / GRPO / 推理时计算(学会复杂推理)
↓
= 你现在用的 LLM本质上,"学知识"对模型来说就是"把概率分布调对"。
2026 新范式:推理时多想 + 会用工具
普通模型像"看到题就立刻答";推理模型像"先在草稿纸上想一会儿,再回答"。
它本质上仍然是一边预测 token,一边生成内容;区别在于复杂任务上会多生成一段内部推理过程,用更多 token 做:
- 分解问题
- 尝试不同路线
- 检查中间结果
- 修正错误答案
- 决定是否调用工具
这叫 test-time compute scaling:不只在训练时花算力,也在推理时花更多算力。
| 能力 | 直觉类比 | 适合任务 |
|---|---|---|
| 普通回答 | 看到题就答 | 闲聊、改写、简单问答 |
| 推理模型 | 先打草稿再答 | 数学、代码、复杂决策 |
| 工具增强 Agent | 边想边查资料、跑代码、读文件 | 实时信息、代码库分析、长任务 |
WARNING
多想不等于一定更真。对数学、代码、逻辑题,更多推理 token 通常有帮助;但对事实性问题,如果模型本来不知道答案,"想更久"也可能只是编出一个更自信的解释。需要实时信息或精确事实时,应该让模型使用搜索、数据库或代码工具。
这也是后面课程要讲工具和 Agent loop 的原因:强 AI 系统通常不是裸 LLM,而是 LLM + 工具 + 上下文管理 + 工作流。
涌现:规模够大时,能力跨过阈值

一个令人惊讶的现象:小模型做不好的事,大模型突然看起来能做了。
| 能力层级 | 典型行为 | 直觉理解 |
|---|---|---|
| 小模型 | 能生成语法基本正确的句子 | 像刚学会说话 |
| 中等模型 | 能写短文、做简单问答,但事实容易错 | 像见过很多例子的学生 |
| 大模型 | 能写代码、总结长文、做多步推理 | 像有经验的助理 |
| 推理/工具增强模型 | 能规划、验证、搜索、运行代码 | 像带草稿纸和工具箱的专家 |
这种"量变引发质变"的现象叫 emergence(涌现)。
为什么会涌现?说实话,至今没有完美解释——这是 AI 领域最活跃的研究问题之一。
不过,2023 年以来的研究提醒我们:有些"突然出现"可能是评测指标造成的错觉。比如模型从 49 分进步到 51 分,如果考试规则是"50 分以下全错,50 分以上算对",看起来就像能力突然跳变。
所以更稳妥的说法是:
- 模型能力确实会随着规模、数据质量、训练方法提升而增强
- 但这种增强不一定真的是魔法式"突然觉醒"
- 很多时候,它只是跨过了某个任务或评测的可见阈值
但工程上我们只需要知道一个公式:
next-token prediction + Transformer + 海量数据 + 后训练 + 推理时计算 + 工具 → 智能表现
一个重要的类比
LLM 的学习过程,其实很像一个小孩学说话。
小孩子从没上过语文课,但通过听大人对话、看动画片、刷手机视频,慢慢就学会了说话。最开始是简单的词——"妈妈""要""不要";然后是短句——"我要喝水";再然后,突然有一天蹦出让你惊掉下巴的话:
"无聊看电视,不无聊不看电视"
"吃饭,吃零食,都得拉屎"
没人教过他这些句子——他是从海量的"语言输入"中,自己总结出了规律,然后组合出了从未听过的新句子。
LLM 也是一样:
| 小孩 | LLM |
|---|---|
| 听大人说话、看动画片 | 读海量甚至万亿级 token 的文本 |
| 从没上过语文课 | 没人逐句教它"这样说才对" |
| 先学会简单词,再学会复杂句 | 规模、数据和训练方法提升后,能力跨过阈值 |
| 偶尔说出惊人的新句子 | 能组合出训练数据里没有的回答 |
| 有时会胡说八道 | 有时会"幻觉"——编造不存在的事实 |
| 没出过家门,不知道外面的世界实时在发生什么 | 不知道训练截止日期之后的信息 |
| 需要看书、问人、用工具确认事实 | 需要搜索、数据库、代码执行等工具补充能力 |
当然,这只是类比,不是说 LLM 真的像小孩一样理解世界。小孩有身体、感官和真实生活经验;LLM 主要从文本、多模态数据和工具反馈中学习模式。
这个类比解释了后面几节要讲的东西:
- 第 4 节"幻觉":小孩胡说八道的部分
- 第 5 节"需要工具":怎么让它获取"家门外"的实时信息
动手试试
运行 demo_01_next_token.py,你会看到:
- 同一个输入在"对话模式"和"续写模式"下,模型选择的 token 完全不同
- 简单常识题("地球围绕")→ 模型非常确信,几乎 100% 选同一个答案
- 不确定的题("2030 年诺贝尔物理学奖得主是")→ 模型犹豫,每次可能给出不同答案
小结
| 概念 | 一句话理解 |
|---|---|
| Next-token prediction | LLM 运行时的基本动作:预测下一个 token |
| 概率分布 | 每个位置都有一张候选词表,按概率排列 |
| 预训练 | 在海量 token 上反复"纠正概率分布" |
| 后训练 | 让模型从"会接龙"变成"会当助手" |
| 推理模型 | 复杂任务上多花 token 计划、检查和修正 |
| 工具增强 | 用搜索、文件、代码执行弥补模型本身的局限 |
| 涌现 | 规模和训练提升后,能力跨过可见阈值 |
| Temperature | 控制采样随机性:低=稳定,高=发散 |
下一节:知道了 LLM 是个"概率预测机",怎么跟它对话?→ 三种角色:system / user / assistant。