第 12 节 · ReAct:Thought-Action-Observation 循环
一句话回答
ReAct = Reasoning + Acting:让模型每一步先输出一段思考(Thought),再输出一个行动(Action),看到结果(Observation)后回到思考,循环往复。
它来自 2022 年 Yao 等人的论文 《ReAct: Synergizing Reasoning and Acting in Language Models》——早于 OpenAI Function Calling。到 2026 年,很多框架已经不用纯 prompt + 正则来实现 ReAct,但 Thought / Action / Observation 仍然是理解 Agent 的核心心智模型。
核心循环
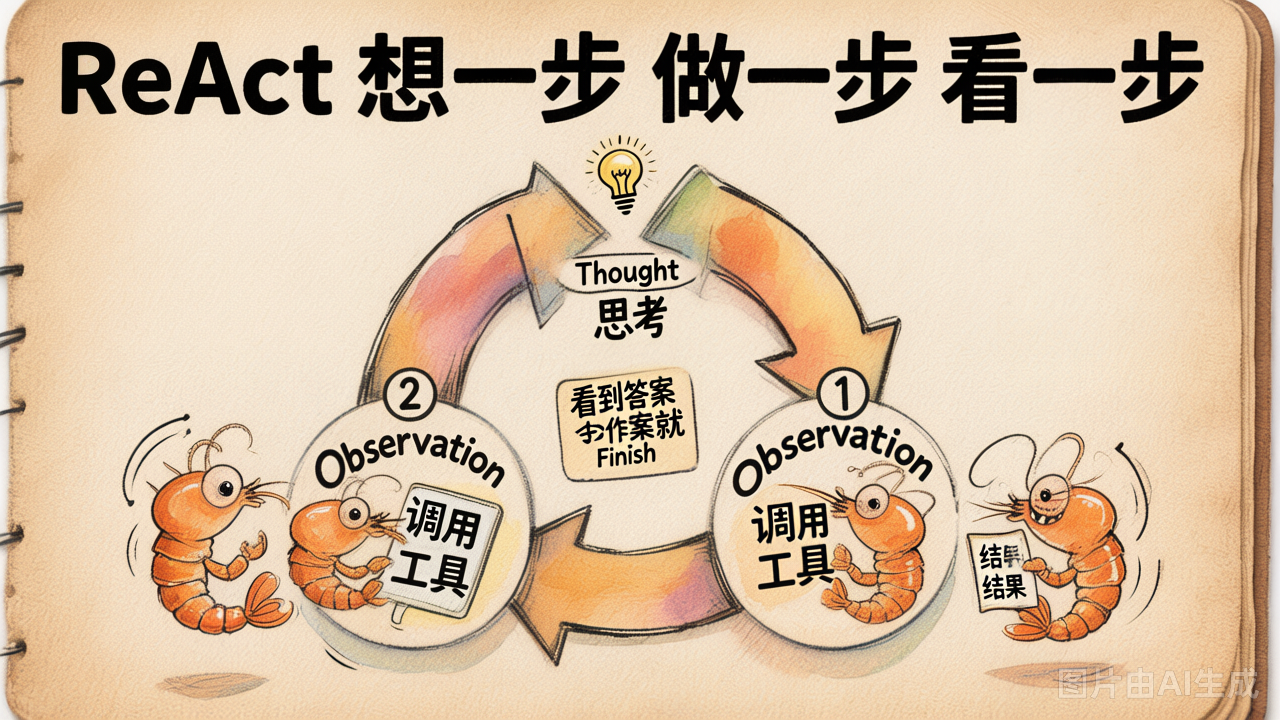
模型每一轮的输出长这样:
Thought: 我需要先查北京天气
Action: get_weather(city="北京")我们的代码用正则把 Action 抠出来执行,把结果作为 Observation 拼回 prompt:
Thought: 我需要先查北京天气
Action: get_weather(city="北京")
Observation: 北京 晴 25°C
Thought: 天气晴朗,我可以推荐户外景点
Action: get_attraction(city="北京", weather="晴")
Observation: 故宫、颐和园、长城
Thought: 信息已经够了
Action: Finish[今天北京天气晴朗 25°C,建议去故宫、颐和园或长城]3 轮循环结束。思考 + 行动 + 观察反复交替——这就是 ReAct 名字的由来。
关键设计:Thought 在不在 prompt 里?
ReAct 的精髓不是"多了个 Action 字段",而是让模型在每次行动前先做一次局部决策。可见的 Thought 让模型有机会:
- 解释为什么调这个工具
- 检查上一轮 Observation 是否符合预期
- 决定接下来该做什么
在早期 ReAct 里,Thought 往往就是完整的 chain-of-thought,直接写进 prompt。2026 年再看,这一点要更谨慎:很多推理模型会把详细推理放在隐藏 reasoning tokens 里,产品界面也不一定适合展示完整思维链。教学 demo 里保留可见 Thought,是为了让你看懂循环;生产系统里更常见的是记录简短理由、计划摘要或可审计轨迹。
跟 Day2 Function Calling 的对比
| 维度 | Day2 Function Calling | ReAct |
|---|---|---|
| 工具调用怎么表达 | OpenAI 协议字段 tool_calls | prompt 里约定的 Action: ... 字符串 |
| 解析方式 | 直接读结构化字段 | 正则解析 |
| 思考过程 | 默认不要求可见 Thought,可额外要求简短理由 | 每步显式写 Thought |
| 健壮性 | 高(协议保证) | 低(模型多说一句就崩) |
| 可读性 | tool_calls 是 JSON,对人不友好 | Thought 让整个轨迹很可读 |
真实工程里:
- 用 Function Calling 表达和执行工具调用(更稳)
- 用 ReAct 风格 prompt 组织决策节奏(先判断当前该做什么,再调用工具)
- 用 tracing 记录每步选择、工具参数和结果,方便 debug / eval
两者不是二选一。Day2 demo 里 system prompt 没要求 Thought,但你可以要求模型给出简短 rationale 或步骤摘要;不要把完整、冗长的隐藏推理链当成业务接口。
为什么 ReAct 至今仍被广泛讨论
- 直觉清晰:Thought-Action-Observation 三个词就把 Agent 工作流讲清楚了
- prompt 即架构:不需要框架,复制一段 prompt 就能跑
- 轨迹可读:即使不展示完整思维链,也能看到每步选择了什么动作、拿到了什么观察
- 是后来很多范式的祖宗:Plan-and-Solve、Reflection、Tree-of-Thoughts 都是在它的基础上变种
2026 推理模型 vs ReAct
推理模型(如 o 系列、R1 类模型)会在内部消耗 reasoning tokens 来做更长的推理,这会减少你手写 Thought: 的必要性,但不会替代 Action + Observation。模型再会"想",也仍然需要外部工具来查实时信息、执行代码、读写文件、跑测试。
所以更准确的说法是:推理模型弱化了可见 Thought 的 prompt 工程价值,但没有替代 Agent Loop 本身。
ReAct 老 paradigm 的脆弱性

写过 ReAct 的人都吃过这些亏:
# 模型乖乖输出
"Thought: ...\nAction: get_weather(city=\"北京\")"
# → 正则能解出来 ✅
# 模型多说了一句
"我先思考一下:\nThought: ...\nAction: ..."
# → 正则可能挂了 ❌
# 模型一次输出两对
"Thought: ...\nAction: ...\nThought: ...\nAction: ..."
# → 该取哪一对?❌
# 模型用了花括号变体
"Action: get_weather('北京')"
# → 单引号?没有 city= 关键字?❌工程版本要做大量 fallback,每加一种容错就多一道坑。这就是为什么 Function Calling 出现后,工程实现逐步从"正则解析模型文本"迁移到"读取结构化 tool_calls"——协议字段比 prompt 约定更可靠,也更容易记录和评测。
但今天我们故意复刻这个老 paradigm,让你亲身体会下:
- 它的优雅(Thought 让推理可读)
- 它的脆弱(一次模型不规矩就崩)
只有写过这两面,你才会真正理解为什么 Function Calling 是行业拐点。
跟 01-hello-react 对应
仓库里 examples/hello-react/ 就是一份标准 ReAct 实现—— agent.py 100 行不到,带工具调用 + 正则解析 + 多轮循环 + 截断兜底。
可以投屏对照看:注意 agent.py 第 26-36 行的"截断多余 Thought-Action 对"——就是为了应对模型一次输出多对的情况。
动手试试
cd labs/03-agent-patterns
python demo_12_react.py会跑 5 个测试任务(详见 toy_agent_base.py 里 TASKS),观察:
- 模型的 Thought 是否合理?
- 哪个任务它能正确 Finish?
- 哪个任务正则解析翻车了?
- 跟 Day2 demo_09 的最小 Agent(用 tool_calls)相比,每步输出的 token 量怎么变化?
小结
| 概念 | 一句话理解 |
|---|---|
| ReAct | Thought + Action + Observation 三段循环 |
| 来源 | 2022 年 Yao 等人论文,先于 Function Calling |
| Thought 的作用 | 解释为什么 + 检查上一步 + 决定下一步 |
| 老 paradigm 的痛 | 纯 prompt 约定 + 正则解析 = 脆弱 |
| 今天为什么仍要学 | 直觉清晰 / 是后来很多范式的祖宗 / 真实工程仍混合用 |
下一节:ReAct 是"走一步看一步"。如果任务步骤多到一定程度,先把整盘棋画出来再下 是不是更稳?→ Plan-and-Solve。