第 14 节 · Reflection:让 Agent 自我反思与修正
一句话回答
Reflection 不是新的 Agent,是一个"包装层"——在底层 Agent 给出答案后,让评审员模型、规则或测试挑刺,再让原 Agent 拿着批注重写。
它的核心命题:起草 → 审阅 → 修订——跟你写论文写代码的过程一样。
三段流程
┌──────────────┐
用户问题 ──► │ 底层 Agent │ ──► 草稿答案
└──────────────┘ │
▼
┌──────────────┐
│ 评审员/Verifier │
│(模型/规则/测试)│
└──────┬───────┘
│
┌───────────────┴───────────────┐
▼ ▼
PASS ──► 提交答案 NEEDS_REVISION
│
▼
┌──────────────┐
│ 原 Agent │
│ + 评审意见 │ ──► 修订版
└──────────────┘
│
▼
回到评审员"包装层"是什么意思
Reflection 的代码主体只有 30 行,因为它不改底层:
def run_with_reflection(question, max_rounds=2):
answer = run_base_agent(question) # ① 底层 Agent 起草
for _ in range(max_rounds):
passed, feedback = review(question, answer) # ② 评审
if passed:
return answer
answer = refine(question, answer, feedback) # ③ 修订
return answer底层 Agent 可以是:
- Day2 的最小 Agent Loop
- demo_12 的 ReAct
- demo_13 的 Plan-and-Solve
- 甚至一个纯 chatbot(不调工具)
这就是为什么把 Reflection 单独作为一节讲——它是正交于"怎么干活"的。 你已经有的任何 Agent,都可以尝试套一层 Reflection;是否值得,要看评审标准和反馈质量。
评审员的 prompt 怎么写
关键是让评审员有一个明确的检查清单,不能光说"你好好检查一下":
REVIEW_PROMPT = """你现在是一个严格的评审员。请检查下面这个答案。
用户问题:{question}
待评审答案:{answer}
# 检查清单
1. 答案是否直接回答了用户的核心诉求?
2. 数字、计算结果是否准确?
3. 是否漏掉了用户问题里的某个子问题?
4. 是否编造了未经证实的信息?
# 输出格式
VERDICT: PASS 或 NEEDS_REVISION
ISSUES:
- 如果 PASS,写"无"
- 如果 NEEDS_REVISION,列出每个问题,每行一条
"""两个关键点:
- 检查清单要具体:模糊的"看看有没有问题"几乎一定输出 PASS
- 输出格式要结构化:VERDICT / ISSUES 两个字段方便程序判断
一个 trick:让评审员"假装挑刺"
模型有一个倾向:对自己刚刚写的东西更宽容。所以即使你写好检查清单,第一次评审经常说 PASS。
工程上常用 trick:
# 在评审 prompt 里加一句
"假设你是一个挑剔的高级工程师,你必须找出至少 3 个可以改进的地方。"这样模型会更认真地挑问题,但也可能产生假问题:为了满足"至少 3 个"而过度修改。它适合教学和低风险写作,不适合直接作为生产质量门禁。
更工业的方案:用更可靠的反馈源当评审员。比如底层用小模型干活,评审员用更强模型;或者用规则 / 测试 / 静态分析 / 检索事实这种外部 verifier(写代码场景特别有效)。
三种范式怎么选
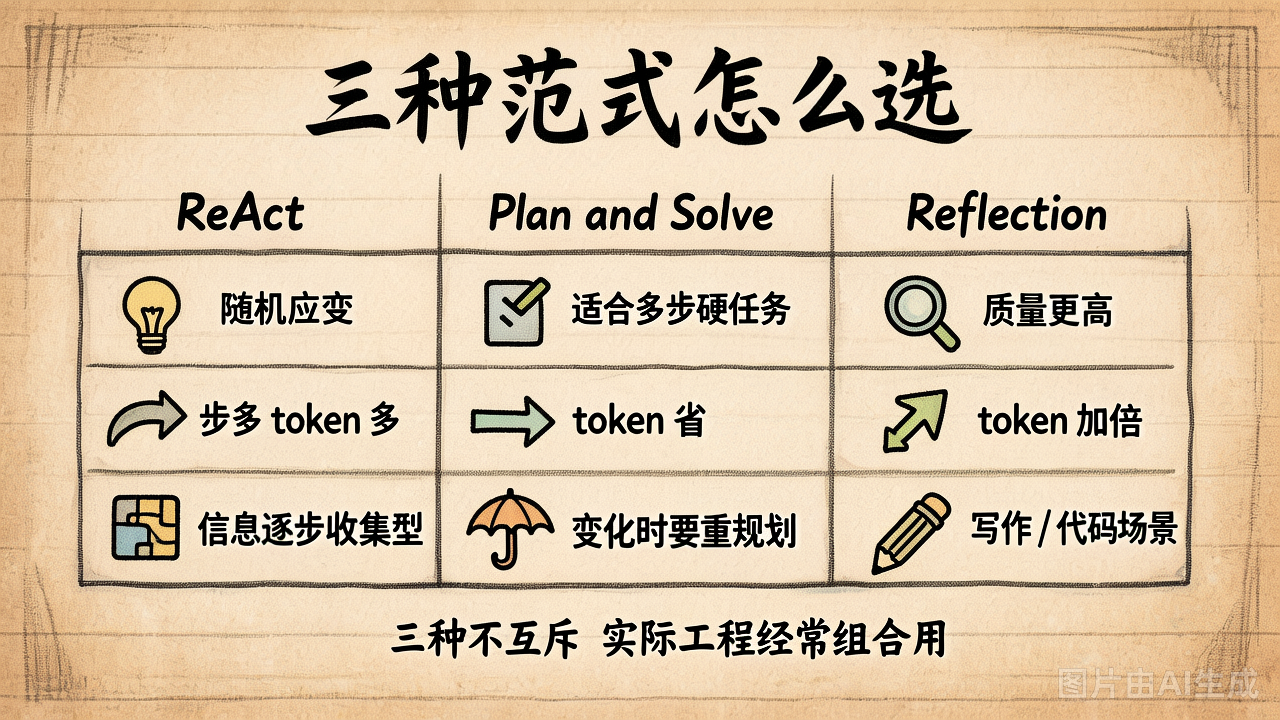
| ReAct | Plan-and-Solve | Reflection | |
|---|---|---|---|
| 决策方式 | 走一步看一步 | 先规划再执行 | 起草 → 审阅 → 修订 |
| token 消耗 | 步多 token 多 | 流程清晰时常更省 | 比 ReAct 多 ~2x |
| 健壮性 | 低(正则解析脆) | 中(计划错了就废) | 取决于评审质量 |
| 适用任务 | 信息收集 / 探索性 | 流程明确 / 多步硬任务 | 写作 / 代码 / 推理 |
| 可解释性 | Thought 写出来的 | Plan 写出来的 | Review 写出来的 |
| 关键风险 | 模型不规矩就崩 | 计划与现实不符 | 自评盲区 / 误报 / 成本上升 |
2026 推理模型与 Reflection 的关系
推理模型会在内部花更多 reasoning tokens 做验证和修正,但这不等于外部 Reflection 已经没用了。大量 self-correction 研究都提醒我们:没有外部反馈时,模型自查可能改善,也可能把对的改错。
更稳的做法是把 Reflection 连接到外部信号:测试结果、静态分析、检索证据、规则校验、更强模型或人工反馈。对于写代码、查资料、算账这类任务,外部 verifier 通常比"模型脑内自信"更可靠。
什么时候不要用 Reflection
Reflection 不是免费午餐。以下场景要谨慎:
| 场景 | 为什么不适合 |
|---|---|
| 简单问答 | 多一次 review 只会增加延迟和成本 |
| 没有明确评价标准 | 评审员容易泛泛而谈或误报 |
| 评审员和生成器能力相同且无外部证据 | 容易自我确认,发现不了关键错误 |
| 强实时任务 | 多轮 refine 会拖慢交互 |
一句话:有清晰检查标准、有外部反馈、质量优先时,Reflection 才更划算。
三种不互斥,工业里经常组合:
# 生产 Coding Agent 的常见组合思路
def solve(task):
plan = planner(task) # ① Plan
for step in plan:
result = react_loop(step) # ② 每步内 ReAct
answer = aggregate(plan, results)
answer = reflection(answer) # ③ 最后一道 Reflection
return answerDay2 vs Day3 的关系
Day2 教的"最小 Agent Loop(带 tool_calls)"是底盘——一个能调工具、能循环的执行引擎。
Day3 三种范式是装在底盘上的三种"驾驶模式":
- ReAct = 走一步看一步的"巡航模式"
- Plan-and-Solve = 先 GPS 规划好的"导航模式"
- Reflection = 终点前再绕一圈检查的"复核模式"
底盘还是 Day2 那个底盘——tools + messages + tool_calls + 循环。不同范式的差别只在 prompt 怎么写、循环怎么组织。
动手试试
cd labs/03-agent-patterns
python demo_14_reflection.py注意几个观察点:
- 第一次 review 通常给 NEEDS_REVISION 还是 PASS?
- Refine 后的答案跟初稿比,主要改了什么?
- token 消耗:跟 demo_12 / demo_13 比,跑同一道题贵了多少?
小结
| 概念 | 一句话理解 |
|---|---|
| Reflection | 起草 → 评审 → 修订 的包装层 |
| 跟 ReAct/PS 的关系 | 正交。底层用任何 Agent 都行 |
| 评审员 prompt | 必须有具体检查清单 + 结构化输出 |
| 常见 trick | "假装挑剔" 强行找问题 |
| 适用 | 写代码、写报告、做推理这类"质量优先"任务 |
| 代价 | token、延迟和误报风险都会上升 |
理论部分到此结束。下面 lab:
- Part 1(50min):把 demo_12 的 ReAct 从参考实现填空补完
- Part 2(50min):把 demo_13 的 Plan-and-Solve 填空补完
- Part 3(30min):套上 Reflection 跑横向对比 + 写 comparison.md